Zhihu Sentiment Classification
Zhihu Sentiment Classification
Introduction
With the development of the Internet, a large number of users on the Internet have written a lot of text,which contain the people’s sentiment. However, due to the huge amount of text, it is impossible to deal with the amount of text on the Internet only by relying on manual means. So we need a Intelligent algorithm to classify the sentiment of text automatically.
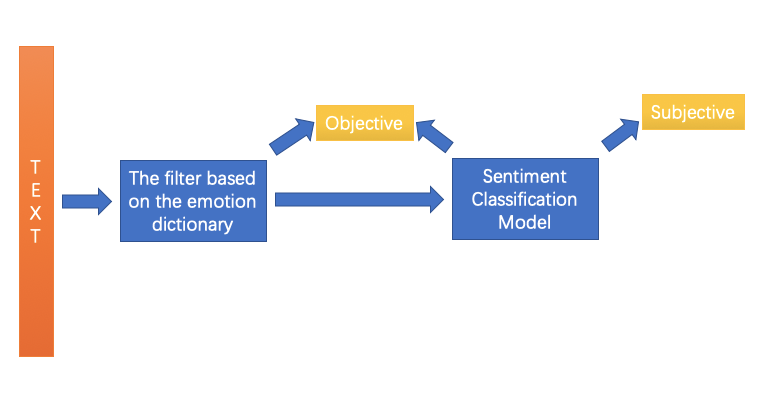
Zhihu is the largest online QA community in China, with 160 million registered users, a large number of users express their opinions on that, and it is important to fetch user’s emotional tendency to a specific topic. Our task is to develop a sentiment classification system to classify the Zhihu texts. Here are some examples of Zhihu texts. Currently, Positive and negative texts are treated as subjective texts and neutral texts are treated as objective texts.
First, we need to establish a benchmark using Zhihu Data, try some text sentiment classification methods, and implement a higher performance subjective and objective classification algorithm. Finally, we need to evaluate the relevant classification methods.
Datesets
We have built two datasets, there are 20k pieces of texts about “Zhihu” in the first dataset. The second data set has about 70k pieces of texts with random topics. Four annotators do the labeling work. After the labeling is completed, 800 samples are randomly selected for manual inspection. The label’s correct rate is about 92%. Label distribution is as follow.

Methodology
1. TF-IDF +Traditional Classification Method
Using TF-IDF as the feature extractor to convert a text to a vector. Secondly, feed the vector into a traditional classification model to train and predict the correspond label. After extracting the text features, we use traditional classification model ,Naive Bayes and Logistic Regression, to do sentiment classification.
2. Word2vec or Bert + CNN or RNN
Here is t the Basic Framework of deep learning method, Firstly, we map the text into a matrix using pretrained word2vec matrix. This word2vec matrix is obtained by training in many corpus. And then we build a neural network to do classification.

Result
2W dataset
| Method | Objective Precision | Subjective Precision | Objective Recall | Subjective Recall | Accuracy |
|---|---|---|---|---|---|
| Naive Bayes | 0.68 | 0.75 | 0.97 | 0.18 | 0.689 |
| Logistic Regression | 0.73 | 0.68 | 0.89 | 0.41 | 0.722 |
| TextCNN | 0.73 | 0.58 | 0.82 | 0.46 | 0.691 |
| Bi-LSTM | 0.74 | 0.60 | 0.82 | 0.47 | 0.699 |
| BERT | 0.79 | 0.65 | 0.82 | 0.61 | 0.746 |

7W dataset
| Method | Objective Precision | Subjective Precision | Objective Recall | Subjective Recall | Accuracy |
|---|---|---|---|---|---|
| Naive Bayes | 0.69 | 0.62 | 0.95 | 0.15 | 0.686 |
| Logistic Regression | 0.71 | 0.57 | 0.89 | 0.28 | 0.691 |
| TextCNN | 0.71 | 0.58 | 0.91 | 0.25 | 0.690 |
| Bi-LSTM | 0.72 | 0.52 | 0.83 | 0.37 | 0.675 |
| BERT | 0.74 | 0.57 | 0.85 | 0.39 | 0.700 |
